Engineering Lab Note: Modern Binary Compression with the Streams API | TiltStack
Engineering Lab Note #03: The Compression Streams Architecture
In my 14 years of engineering, I’ve spent a disproportionate amount of time debugging "Out of Memory" (OOM) errors in Node.js services caused by poorly managed buffers during compression tasks. Whether it's log rotation or API response gzipping, the standard approach has always been: "Send the data to the server, let the server compress it, and send it back."
This is, architecturally speaking, a performance and privacy leak. If you have a 5MB JSON payload that you need to Base64 encode or Gzip for a configuration file, you shouldn't have to transmit that 5MB over the public internet.
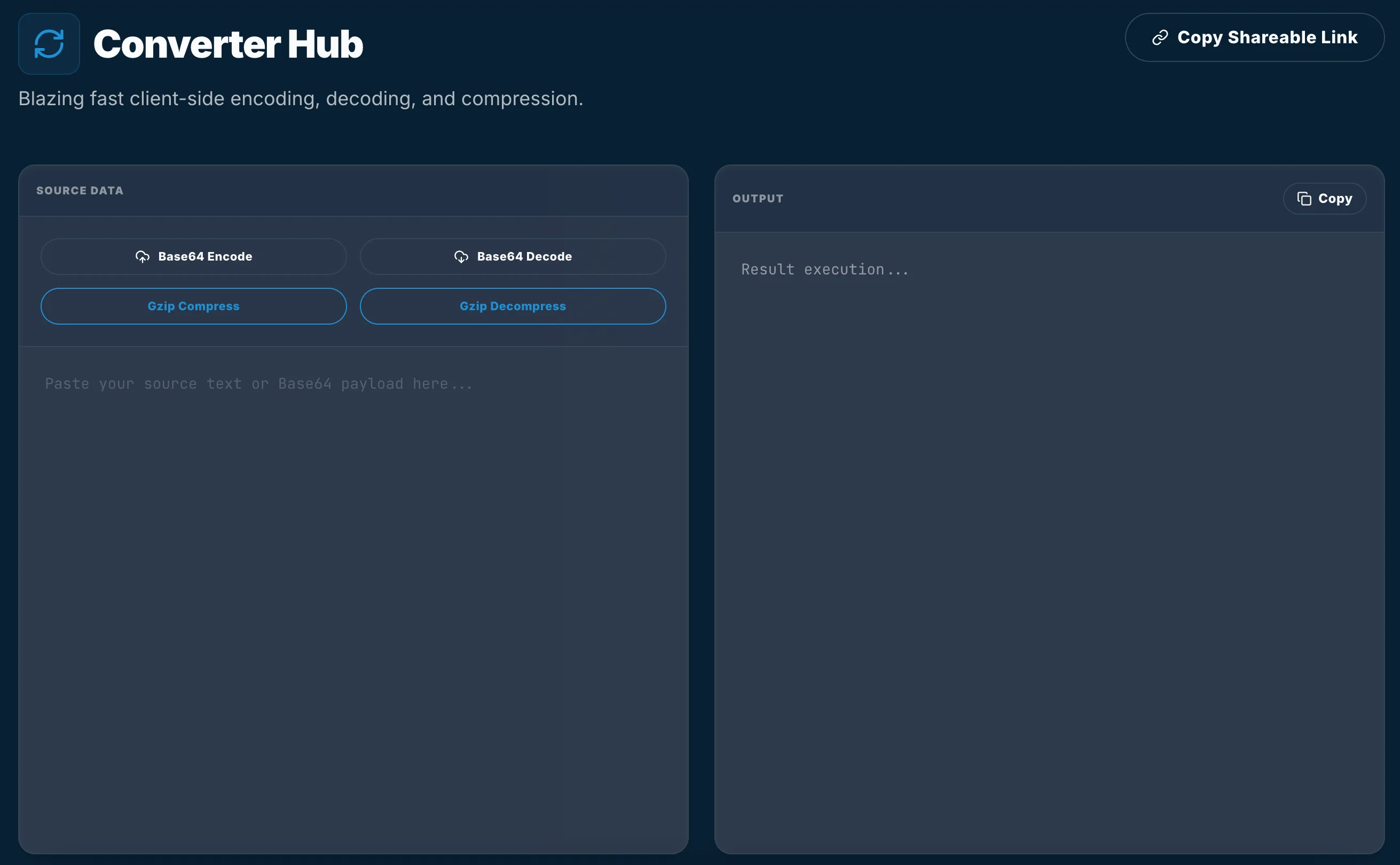
When we built the TiltStack Converter Hub, we decided to bypass the server entirely and leverage a relatively new but extremely powerful set of APIs: Compression Streams.
The Death of pako and Synchronous Bloat
For years, the gold standard for client-side Gzip was a library called pako. It’s a great piece of software, but it’s heavy (~45KB minified) and, more importantly, it usually runs synchronously on the main thread. If you try to deflate a large string using a synchronous library, the browser's UI will lock up until the task is finished.
The DevSuite is built for speed. We don't use large third-party dependencies for core operations if the platform provides a native alternative. Modern browsers now expose the Compression Streams API, which allows us to perform Gzip (deflate) and Gunzip (inflate) operations asynchronously using standard web streams.
Implementing Asynchronous Gzip
The key advantage of the Streams API is its ability to handle data in "chunks" rather than loading the entire payload into memory at once. This is vital for maintaining a responsive UI when dealing with massive datasets.
// The local-first compression pipeline
async function compressString(input: string): Promise<Uint8Array> {
const stream = new Blob([input]).stream();
const compressionStream = new CompressionStream('gzip');
const compressedStream = stream.pipeThrough(compressionStream);
// Convert the stream back to a buffer
const response = new Response(compressedStream);
const blob = await response.blob();
return new Uint8Array(await blob.arrayBuffer());
}
By piping the input through a CompressionStream, we leverage the browser's internal engine (usually written in optimized C++ or Rust) to handle the deflate algorithm. Because this returns a ReadableStream, we can handle the result as a Promise, keeping the UI thread free for secondary interactions.
The Base64 Performance Reality
Base64 encoding is another area where "junior" implementations fall short. Many developers still use btoa() and atob(). These are legacy APIs that only work with Latin1 strings. The moment you introduce a single UTF-8 character (like an emoji or localized text), they throw a DOMException.
In the Converter Hub, we use a more robust FileReader or TextEncoder approach to ensure multi-byte characters are handled correctly before encoding.
// Deterministic UTF-8 to Base64
const encodeBase64 = (str: string) => {
return btoa(encodeURIComponent(str).replace(/%([0-9A-F]{2})/g,
(match, p1) => String.fromCharCode(parseInt(p1, 16))));
};
Why Privacy-First Matters for Metadata
A lot of the data developers compress or encode is sensitive metadata: JWTs, environment variables, or minified configuration objects. Sending these to a "Free Converter" is an invitation for that data to end up in a persistent traffic log.
By building on the Compression Streams API, we offer an architecture where:
- The CPU is Local: We use your machine's power, not ours.
- The Memory is Ephemeral: Buffers are cleaned up by the garbage collector as soon as the stream finishes.
- The Data is Sealed: No network packets are ever generated for the transformation process.
At TiltStack, we believe your development sandbox should be yours alone. Stop uploading your secrets just to compress them.